



大小端和字节对齐
本文最后更新于 2025-10-16,文章内容可能已经过时。
大小端
什么是大小端?
目前在各种体系结构的计算机中,主要采用的字节存储机制主要有两种:大端(Big-endian)和小端(Little-endian)。
大端模式,数据的高字节,保存在内存的低地址中,数据的低字节,保存在内存的高地址中,而数据的取出使用是从低地址开始的,所以大端数据相当于从高字节取出使用
小端模式,数据的低字节,保存在内存的低地址中,数据的高字节,保存在内存的高地址中,而数据的取出使用是从低地址开始的,所以小端数据相当于从低字节取出使用
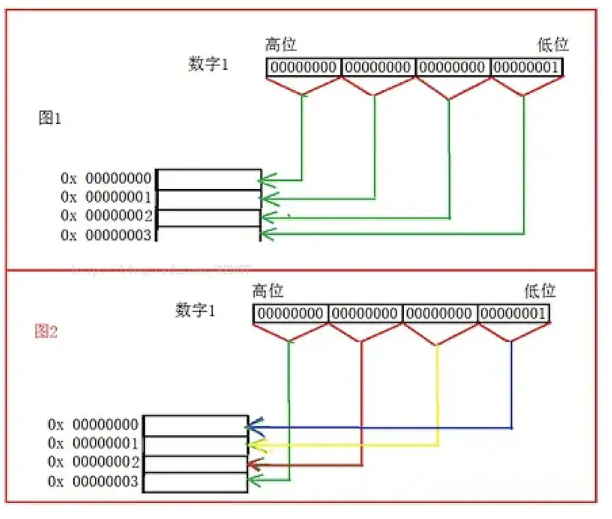
为什么会有大小端模式之分?
因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit。
对于位数大于 8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节。那么必然存在着一个如何将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式
用法
部分x86芯片还存在有些使用小端的芯片,所以使用此芯片的电脑采用小端存储,而网络上传输的数据采用的是大端,所以需要大小端转换
注意
大端小端是对于大于一个byte的数字才有的,如word,dword,int,long等,而byte是没有大小端之分的
memcpy_h2n(byte dest[], struct source)函数可以实现结构体到byte数组的转换,这里会自动把小端转换成大端,所以不需要先在结构体中转换大小端
字节对齐
什么是字节对齐?
引用百度百科里面的一句话:
现代计算机中内存空间都是按照byte划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定类型变量的时候经常在特 定的内存地址访问,这就需要各种类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐
为什么要考虑字节对齐?
平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的。某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
性能原因:数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问,而对齐的内存访问仅需要一次访问。
对齐规则
每个特定平台上的编译器都有自己的默认“对齐系数”(也叫对齐模数)。可以通过预编译命令 #pragma pack(n),n = 1,2,4,8,16 来改变这一系数。
有效对其值:是给定值 #pragma pack(n) 和结构体中最长数据类型长度中较小的那个,有效对齐值也叫对齐单位。
结构体第一个成员的偏移量(offset)为0,以后每个成员相对于结构体首地址的 offset 都是该成员大小与有效对齐值中较小那个的整数倍,如有需要编译器会在成员之间加上填充字节。
结构体的总大小为有效对齐值的整数倍,如有需要编译器会在最末一个成员之后加上填充字节。
